Sample Experiments
The directory sample_experiments contains all the .yml config files and results of Experiment 2 and Experiment 3:
- Experiment 2 aims at assessing, in a reproducible environment thanks to LaikaLLM, the impact of the personalization strategy introduced in the P5 paper,
by using the same prompts defined in the mentioned paper
- Experiment 3 aims at evaluating LaikaLLM performances by varying the LLM backbone and use a novel set of more informative prompts.
Majority of the runs overcame results of the mentioned P5 paper. The new set of prompts can be found here
Each result directory contains a table storing metrics results for each task in both .csv and .tex format, generated with LaikaLLM.
All runs have been tracked with WandB. The full workspace is available by clicking the following image:
![]()
Note: additional experiments can be found in the other_exp
subfolder!
Experiment 2 results
These are the results of the T5-S LLM, with (+W) and without personalization, when trained and evaluated on the Sequential, Direct and Rating Prediction tasks with the P5 prompts. The P5 prompts used can be found here
The evaluation is carried out on a seen prompt and an unseen one.
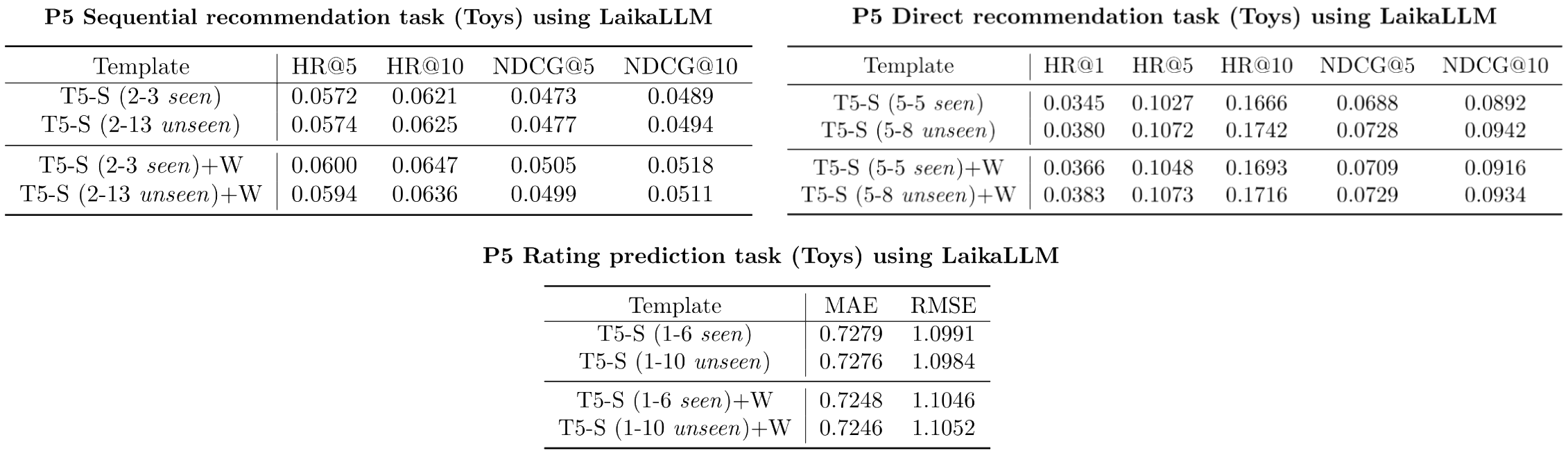
- T5-S: [.yml config][Results directory][Visualize in WandB]
- T5-S + W: [.yml config][Results directory][Visualize in WandB]
Experiment 3 results
These are the results of T5-S, FlanT5-S, FlanT5-B, GPT2, with (+W) and without personalization, when trained and evaluated on the Sequential, Direct and Rating Prediction tasks with the novel set of prompts defined in LaikaLLM. The evaluation is carried out on all prompts, already seen by the model during the fine-tuning phase, and in the following table there are reported the best results for each metric achieved by any prompt of the specific task (best-seen).
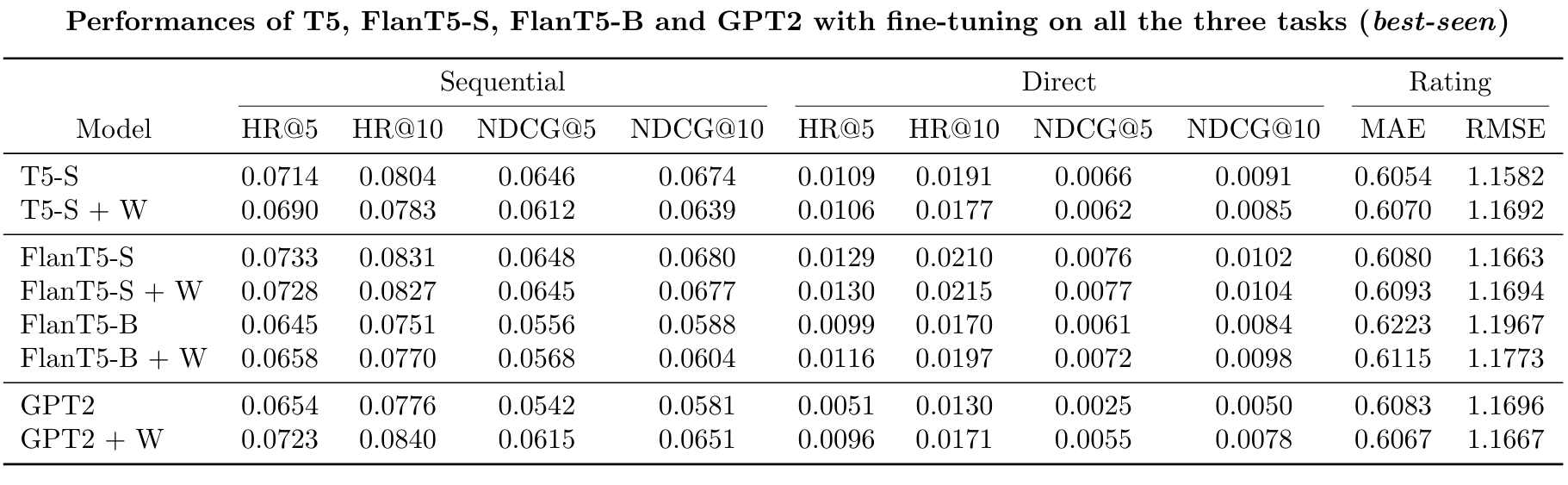
T5 Runs
- T5-S: [.yml config][Results directory][Visualize in WandB]
- T5-S + W: [.yml config][Results directory][Visualize in WandB]
Flan T5 Runs
- FlanT5-S: [.yml config][Results directory][Visualize in WandB]
- FlanT5-S + W: [.yml config][Results directory][Visualize in WandB]
- FlanT5-B: [.yml config][Results directory][Visualize in WandB]
- FlanT5-B + W: [.yml config][Results directory][Visualize in WandB]
GPT2 Runs
- GPT2: [.yml config][Results directory][Visualize in WandB]
- GPT2 + W: [.yml config][Results directory][Visualize in WandB]